什么是 ChatGPT
它能把知识压缩起来,并且加个聊天界面,供你交互。
有的人说 ChatGPT 是对全人类知识的有损压缩形式。
老实说,我没见过哪个压缩包能配一个搜索框的,更别说有个聊天界面了。
如果不考虑“交互界面”,ChatGPT 算有损压缩、人脑不也是?
它更像一张“数据互联网”,连接所有数据,让问题更接近方案
数据在不同“格式”间转化,越来越快,越来越符合细分需要。格式不只是图片格式、文本格式:
- 想为纸质书添加电子书摘,最早是要抄录,后来有了各种OCR付费软件、少量要折腾的免费OCR,再到现在,iOS系统自带本地OCR功能
- 有一部分人觉得视频、音频信息密度太低,一般不会通过看视频、听音频学习。但有些资料只在音视频有,怎么办?现在开源的Whisper可以做到把它们转为文字,还有人通过配合LLM,将长视频转化为高质量图文
- 文字生成图片,文字生成视频
- 甚至能缩短外部数据“进入人脑”,并且成为“人体数据”的“距离”
- ……
本节,无基础要求的部分结束
本节要求理解数学或编程中的“函数”概念(施工中)
理论部分
可视化:LLM Visualization (bbycroft.net)
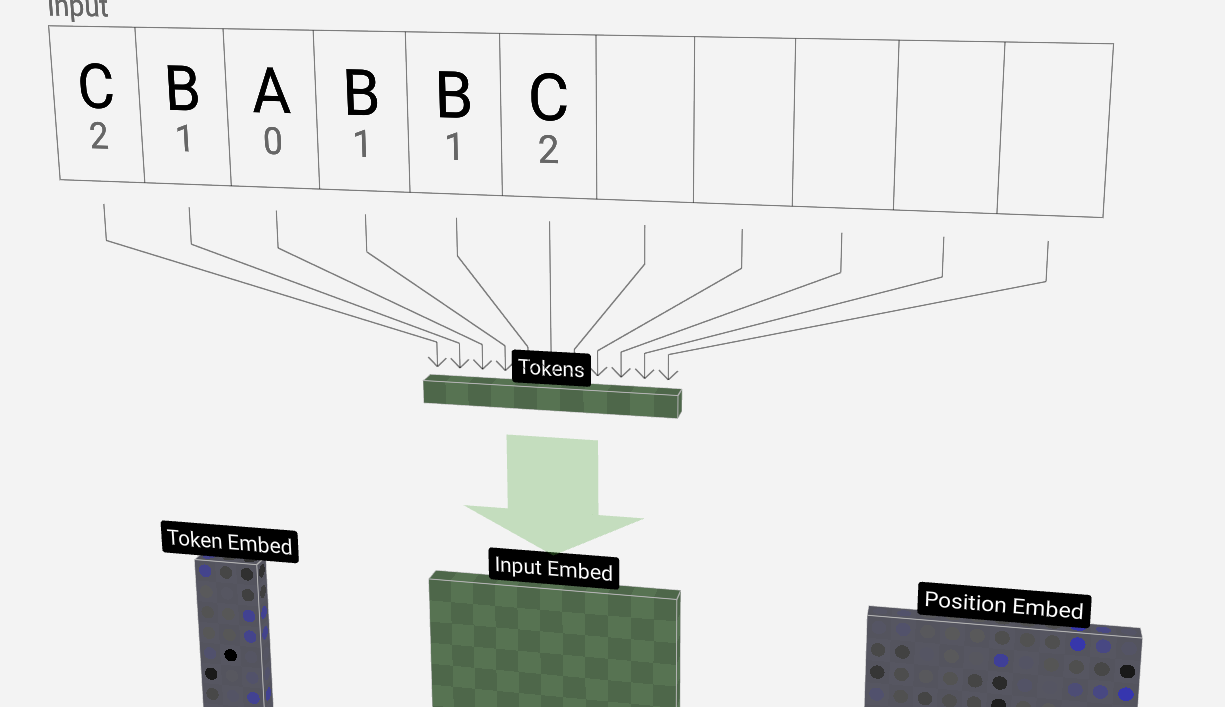
分词器(Tokenizer)
大模型的“单词表”跟平常人的不太一样,比如我们人看 token 是一个词,但是大模型可能是看成 tok 跟 en 两个词。
为什么要这样划分?一个原因是,这样可以大幅度减少单词表的词汇量,原理是字节对编码(BPE)
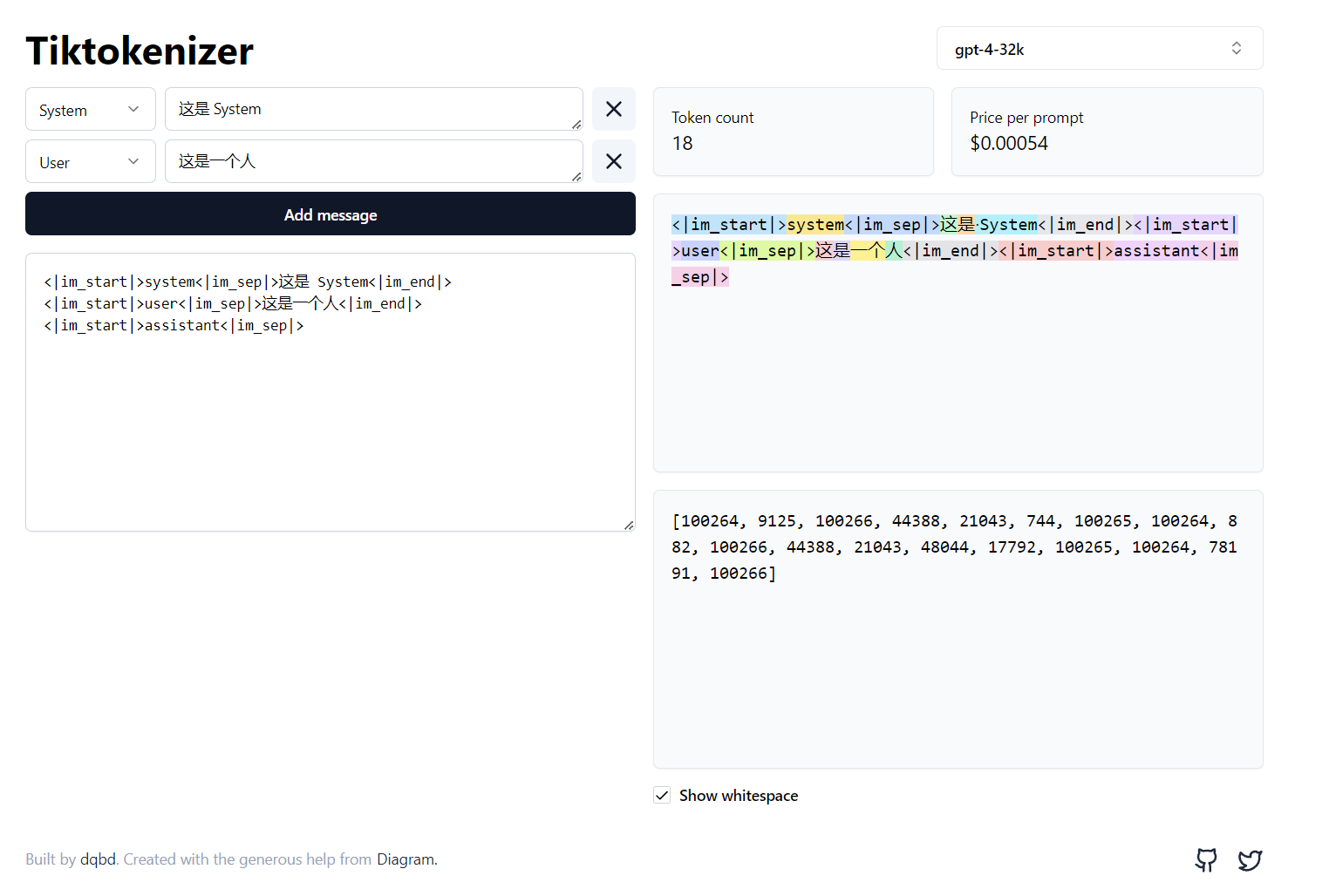
OpenAI 官方开源的分词器是tiktoken,看来他们很喜欢tiktok。如果你想在线体验一番,这个工具,tiktokenizer 是一个好选择
如果你想动手实现一个 GPT-2 的分词器,可以看看 Andrej Karpathy 的 Youtube 视频 Let's build the GPT Tokenizer
如果你了解其中原理,那么你很可能会懂得:
- 为什么大模型的英文表现总是比其他语言更好?
- 跟大模型对话,使用 YAML 格式还是 JSON 格式?
- 为什么有的大模型算术题不好?
其他待施工部分
精力有限,不一定能完成,急的话,请参考: